The aXMonitor plugins are today updated to version 1.3.2. If you have already bought one of the aXMonitor plugins, you can download the update from your account. You should remove any old versions of the plugin from your system to avoid any conflicts.
Today’s update is all about getting more flexibility and personalisation for binaural rendering of Ambisoinics. This is probably the most requested feature update for any of my plugins, so I am very happy to be able to announce the new feature:
- Load an HRTF stored in a .SOFA file for custom binaural rendering.
This allows you to produce binaural rendering for up to seventh order Ambisonics with whatever HRTF you want, providing you with the flexibility you need to produce the highest quality spatial audio content possible.
If you aren’t sure why so many people want personal HRTF support, keep reading.
Advantages of Personalised Binaural
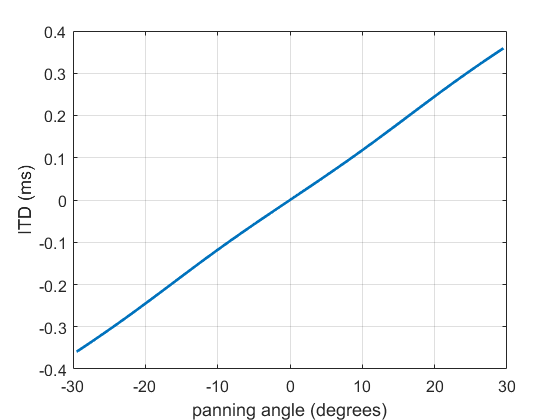
Binaural 3D audio can be vastly improved by listening with a personalised HRTF (head related transfer function). It’s the auditory equivalent of wearing someone else’s glasses vs wearing your own. Sure, you can see most of what is going on with someone else’s glass, but you lose detail and precision. Wear your own and everything comes into focus!
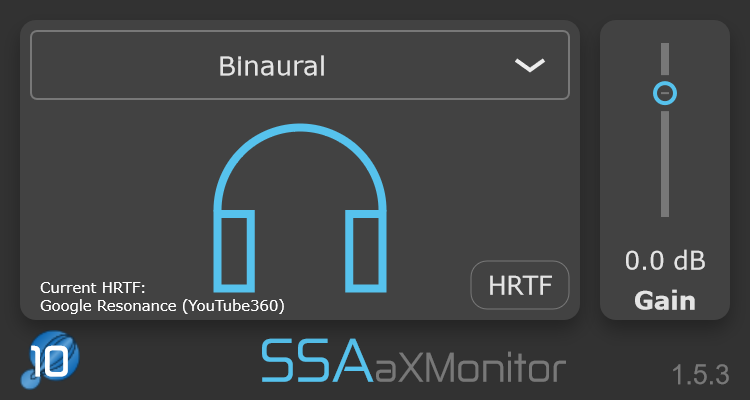
With that in mind, the aXMonitor plugins have been updated to allow you to load a custom HRTF that is stored in a .SOFA file. Now you can use your own individual HRTF (if you have it) or one that you know works well for you. Once an HRTF has been loaded it will be available across to all instances of the plugin in other projects.
What is a .SOFA file?
A .SOFA file contains a lot of information about a measured HRTF (though it can be used for other things as well). You can read more about them here.
Where to get custom HRTFs
You can find a curated list of .SOFA databases here. The best thing to do is to try a few of them until you find one that gives you an accurate perception of the sound source directions. Pay particular attention to the elevation and front-back confusions, since these are what personalised HRTFs help most with.
If you want an HRTF that fits your head/ears exactly then your options are bit more limited. Either you can find somewhere, usually an academic research institute, that has an anechoic chamber and the appropriate equipment. Then you put some microphones in your ears and sit still for 20-120 minutes (depending on their system). Once it’s done, you have your HRTF!
But if you don’t fancy going to all of that trouble, there are some options for getting a personalised HRTF more easily. A method by 3D Sound Labs requires only a small number of photographs and they claim good results. Finnish company IDA also offers a similar service.
Get the aXMonitor
So if you like the sound of customised binaural rendering then you can purchase the aXMonitor from my online shop. Doing so will help support independent development of tools for spatial audio.