My first plugin release was a free first order encoder called the o1Panner. Today it gets an update to version 1.0.1 and a new name. Here is a list of the updates:
name change from o1Panner to a1Panner to match the naming convention of the rest of the aX Ambisonic Plugins.
Today the aXMonitor plugins get their first major update to version 1.2.2. There are two major updates and one minor updates. Let’s start with the major updates:
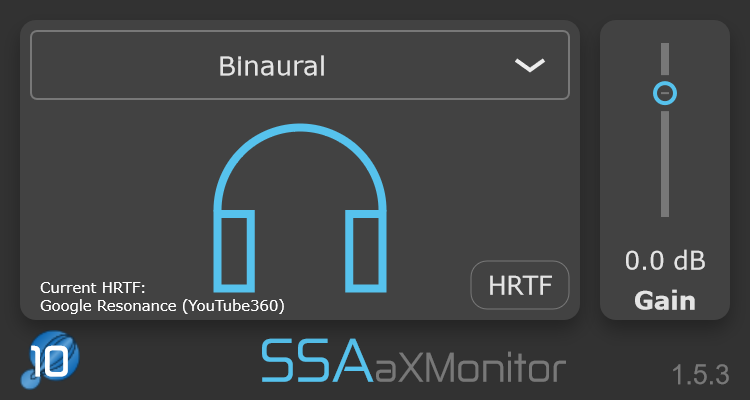
The HRTFs used for binaural 3D sound have been regenerated using Google’s own Resonance Audio toolkit for VR audio. These are the same HRTFs used by Google in YouTube 360. The code released by Google is only up to 5th order, but was actually quite simple to extend to 7th order.
A gain control has been added to boost or cut the overall level for convenience.
The minor update is a fix to make sure the plugin reports the correct latency to the host when using the Binaural or UHJ Super Stereo (FIR) methods.
Google have just open sourced their Resonance Audio SDK, including all sorts of tools for spatial audio rendering. This update to ensures that you can aXMonitor ensures that you can mix your content on HRTFs that will be widely used across the industry.
The aXMonitor is available in 3 versions, providing up to first, third and seventh order Ambisonics-to-binaural decoding.
So if you’d like to start mixing your VR/AR/MR audio content just head over to my store. With your support, I can continue to update the aX Ambisonics Plugins to bring you the tools you want and need.
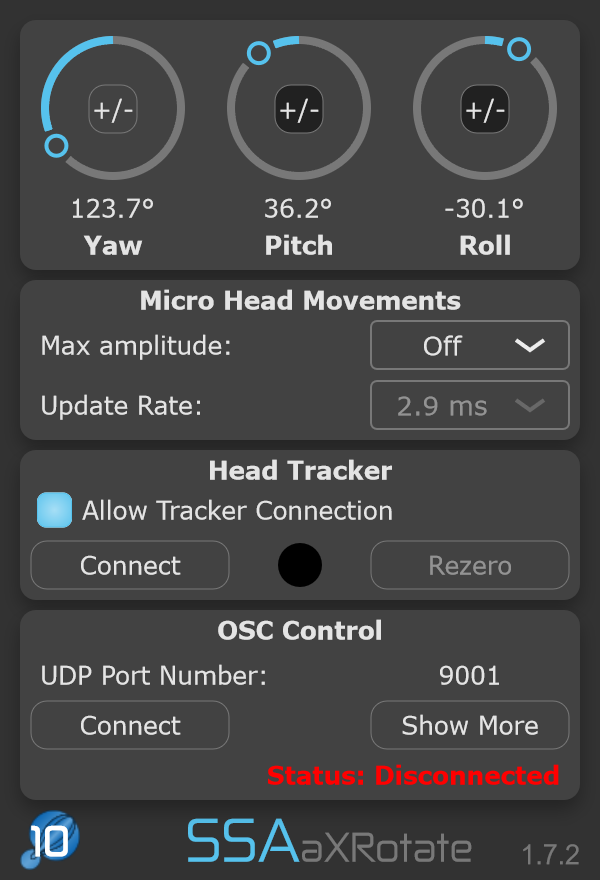
The aXRotate plugin receives an update today to version 1.2.0 and it’s a big one! What’s more, it now comes as a (Universal Binary) AudioUnit format for Mac!
If you have already bought it, you can download the update from the download section of your Account page. If you haven’t, you can pick it up at my online shop!
Version 1.0.0 was a plain vanilla Ambisonics rotation with yaw, pitch and roll control. Version 1.2.0 adds two new features that massively increase its usefulness:
Get head tracking by connect an EDTracker module.
Increase the spaciousness of your static binaural mixes by adding micro oscillations to the sound scene.
MOOCs can be a great way of following a world-class course on a topic without having to enrol in a university and pay the associated fees.
For those interested in spatial audio (and audio more generally) there is a MOOC starting on 23rd October called the Fundamentals of Communication Acoustics that looks like it covers a lot of important topics. It’s followed up by Applications of Communication Acoustics.
I’m considering auditing these, because it never hurts to refresh the basics and the course is taught by some very talented people so I’ll probably even learn plenty of new things!
This post is part of my What Is… series that explains spatial audio techniques and terminology.
OK, you know what stereo is. Everyone knows what stereo is. So why bother writing about it? Well, because it allows us to introduce some links between the reproduction system and spatial perception before moving on to systems which use much more than 2 loudspeakers.
Before going any further, this post will deal with amplitude panning. Time panning will be left for another day. I also won’t be covering stereo microphone recording techniques because that could fill up its own series of posts.
The Playback Setup
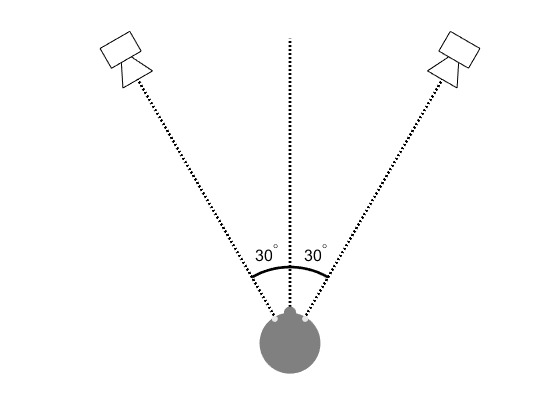
A standard stereo setup is two loudspeakers placed symmetrically at (pm30^{circ}) to the left and right of the listener. We will assume for now that there is only a single listener equidistant from both loudspeakers. The loudspeaker basis angle can be wider or narrower but if they get too wide there is a hole-in-the-middle problem. Too narrow and we reduce the range of positions at which the source can be placed. Placing the loudspeakers at (pm30^{circ}) gives a good compromise between these two, balancing sound image quality with potential soundstage width.
A standard stereo listening arrangement.The tangent law prediction of perceived source angle for different level differences
Placing the Sound
Amplitude panning takes a mono signal and sends copies to the two output channels with (potentially) different levels. When played back over two loudspeakers the level difference between the two channels controls the perceived direction of the sound source. With amplitude panning the perceived image will remain between the loudspeakers. If we know the level difference between the two channels then we can predict the perceived direction using a panning law. The two most famous of these are the tangent law and the sine law. The tangent law is defined as begin{equation} frac{tantheta}{tantheta_{0}} = frac{G_{L} – G_{R}}{G_{L} + G_{R}} end{equation} where (theta) is the source direction, (theta_0) is the angle between either loudspeaker and the front (30 degrees in the case illustrated above) and (G_{L}) and (G_{R}) are the linear gains of the left and right loudspeakers.
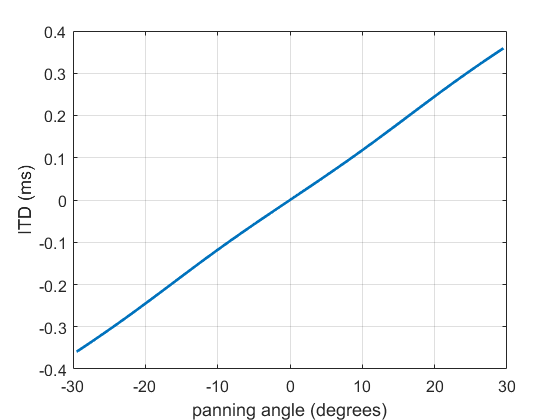
The ITD produced for a source panned with loudspeaker level differences generated by the tangent law.
How It Works
Despite being simple conceptually and very common, the psychoacoustics of stereo are actually quite complex. We’ll stick to discussing how it relates to the main spatial hearing cues.
As long as both loudspeakers are active, signals from both loudspeakers will reach both ears. Due to the layout symmetry, both ears receive signals at the same time but with different intensities corresponding to the level differences of the loudspeakers. Furthermore, since it has further to travel, the signal from the left loudspeaker will reach the right ear slightly later than the signal from the right loudspeaker. The opposite is true for the right ear. This time difference combined with the intensity difference gives rise to interference that generates phase differences at the ears. These phase differences are interpreted as time differences, moving the sound between the loudspeakers.
The ITD (below 1400 Hz) is shown in the figure and is roughly linear with panning angle. This is pretty close to exactly what we see for a real sound source moving between these angles. This works pretty well for loudspeakers at (pm30^{circ}) or less, but once the angle gets bigger the relationship becomes slightly less linear.
These strong, predictable ITD cues mean that any sound source with a decent amount of low frequency information will allow us to place the image pretty precisely. Content in higher frequency ranges won’t necessarily be in the same direction as long frequency content because ILD becomes the main cue.
Even though stereo gives rise to interaural differences that similar to those of a real source, that does not mean it is a physically-based spatial audio system (like HOA and WFS). The aim is to produce a psychoacoustically plausible (or at least pleasing) sound scene. Psychoacoustically-based spatial audio systems tend to use the loudspeakers available to fit some aim (precise image, broad source) without regards to if the resulting sound scene ressembles anything a real sound source would emit.
So, there you have a quick overview of stereo from a spatial audio perspective. There are other issues that will be cover later because they relate to other spatial audio techniques. For example, what if I’m not in the sweet spot? What if the speakers are to the side or I turn my head? What if I add a third (or forth or fifth) active loudspeaker? Why do some sounds panned to the centre sound elevated? All of these remaining and non-trivial points shows just how complex perception of even a simple spatial audio system can be.
This post is part of the What Is… series that explains spatial audio techniques and terminology.
Spatial hearing is how we are able to locate the direction of a sound source. This is generally split in to azimuth (left/right) and elevation (vertical) localisations. Knowing how we localise is essential to understanding the spatial audio technologies. Human spatial hearing is a complex topic with lots of subtleties so we’ll ease in with some of the main concepts.
Interaural Time Difference (ITD)
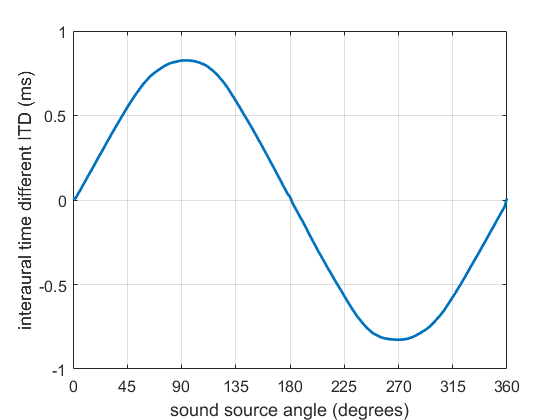
ITD for a Neumann KU100 dummy head averaged across all frequencies below 1400 Hz
Consider a single sound source near to a listener. The sound source will radiate sound waves that will travel through the air to listener. These waves will reach the nearer (ipsilateral) ear of the listener earlier than the further (contralateral). This produces a time difference between the signals at both eardrums known as the interaural time difference (ITD). The brain can extract the time difference by comparing the two signals and will use this as an estimate of the direction of the sound. Whichever ear is leading in time dictates whether the sound is heard to the left or the right. The graph shows the average ITD for frequencies up to 1400 Hz. It has a clear sinusoidal shape that varies predictably with azimuth, making it a useful localisation cue.
ITD cues are mainly evaluated at low frequencies (below approximately 1400 Hz). This is the frequency range at which the wavelength of the sound is long enough when compared to the size of the head to avoid phase ambiguity. Above this frequency the phase can “wrap” around and it not possible to tell if there have been, say, 0.5 cycles, 1.5 cycles etc.
Luckily, we can use another method to localise in higher frequencies.
Interaural Level Difference (ILD)
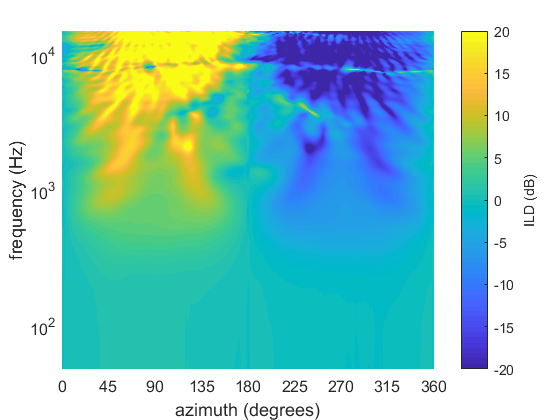
Interaural level difference (ILD) for a Neumann KU100 dummy head in the horizontal plane up to 15 kHz
As frequency increases and the wavelength becomes shorter than the size of the listener’s head, acoustic shadowing becomes important, producing an interaural level difference (ILD). The shadowing causes the level at the contralateral ear to be reduced compared to the ipsilateral. This is in contrast to low frequencies where the wavelengths are so large that the level differences to not vary significantly with source direction (unless the sound source is very close!).
Where ITD exhibits a sinusoidal shape, making direction estimation relatively simple, ILD can vary in a complex manner with source direction. This is due to how the sound waves interact with the head and doesn’t mean that the biggest level difference happens as \(pm90^circ\). In fact, this ILD is actually lower at \(pm90^circ\) than at some less lateral positions. This is known as the acoustic bright spot. The complex ILD patterns are shown in the graph where the more yellow/blue the colour the larger the ILD. Yellow means the left ear is greater than the right and blue the right is greater than the left.
ITD and ILD are work well for differentiating between left and right. But imagine a sound source starts directly infront of you, moves in an arc over your head to finish directly behind you. At no point do ITD and ILD have any value other than zero but we can still perceive the elevation of the sound source. How are we able to do this?
Spectral Cues
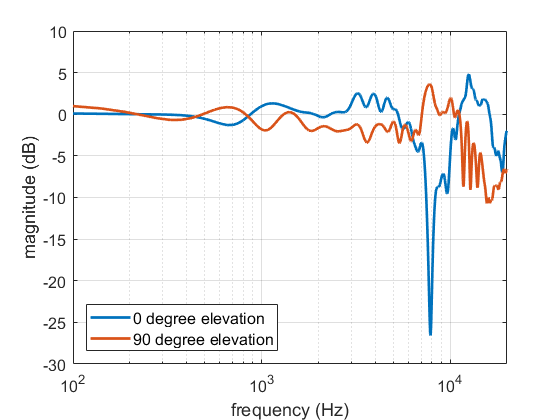
The frequency spectra for a sound source directly in front of and above the listener. Note the significant notch at 8 kHz for the frontal source that is missing in the elevated source.
The outer ears (pinnae) are a very complex shape. They cause the sounds to be filtered in a way that is highly direction dependent. This leads to peaks and notches in the frequency response of the source spectrum that can be used to evaluate the direction, primarily for elevation. The frequencies of the peaks and notches are highly individual, depending strongly on the shape of the outer ears. This is something that the brain learns and it can use this internal template to incoming sounds and give an estimate of localisation.
For example, the graph to the left shows the frequency spectra for a sound source at two different positions: in front and above. The frontal source has a deep notch at 8 kHz which is not the case for the elevated source. This could be used to differentiate between the two elevations, even though the signals at the left and right ears would be (nearly) identical.
Localisation accuracy tends to be much less accurate for elevation than it is for azimuthal (left/right) judgements. This can have implications for how we might design a spatial audio system or on how well they can work.
Is that it?
Not by a long shot! We haven’t covered things like interaural envelope difference, distance estimation, the effect of head movement, the precedence effect, the ventriloquist effect but these are the main principles we need to understand to get to grips with the basics of spatial audio.
This post is the first in a What Is… series. The idea is to explain different techniques, terminology and concepts related to spatial audio. This will range from the most common terms right through to some more obscure topics. And where better to start than “spatial audio” even means!
Spatial audio (with some exceptions) has generally been confined to academia but is rapidly finding applications in virtual reality (VR). There are even moves to bring it to broadcasting so it can be enjoyed by people in the comfort of their living rooms. As spatial audio moves from labs to living rooms it is worth exploring all of the different techniques that have been developed up to this point.
However, defining spatial audio can quickly become rather philosophical. For example, is a mono recording spatial audio? If I take a single microphone to a concert hall and record a performance then I have captured the sense of space, through echoes and reverberation, not just the performances themselves. This means that the space is encoded into the signal – we can tell if a recording is made in a dry studio or a cathedral. For the purposes of this series I will not be considering this to be spatial audio. Instead, I will be defining spatial audio as any audio encoding or rendering technique that allows for direction to be added to the source. How well this is reproduced to the listener will depend on the encoding and playback system but, in general, a spatial audio system will allow different sounds placed in different positions to be directionally differentiated.
There are a large number of different spatial audio techniques available and which one you want to use will depend on the final use. These techniques include (but are in no way limited to):
Stereophony
Vector Base Amplitude Panning (VBAP)
Ambisonics and Higher Order Ambisonics (HOA)
Binaural rendering (using HRTFs over headphones)
Wave Field Synthesis (WFS)
Loudspeaker diffusion
Discrete loudspeaker techniques
Each of these will be explained in more detail in future posts but you can see from this non-exhaustive list that there are already quite a few techniques to choose between. To further complicate things, some of these techniques can be combined in order to take advantage of different properties of both. For example, Ambisonics and binaural can be combined in VR and augmented reality (AR) to give a headphone-based rendering that can be easily rotated (a nice property of Ambisonics).
Spatial audio techniques can also be divided between those that aim to produce a physically accurate sound field in (at least some of) the listening area and those that are not concerned with matching a “real” sound field. HOA and WFS can both be used to recreate a holophonic sound scene using an array of loudspeakers. Meanwhile, stereo and VBAP do not recreate any target sound field but are still able to produce sounds in different directions.
Whether or not the spatial audio technique is physically-based or not, we also have to consider the potentially most important element in the whole chain: the listener! All of these techniques rely on how we perceive the sound and there are any number of confounding factors that can take our nicely defined (in a mathematical sense) system and throw many of our assumptions out the window. Therefore, this What Is… series will also include elements of spatial hearing and psychoacoustics that are essential to consider when working with spatial audio.
So, spatially audio can take a number of forms, each with their own advantage, disadvantages, limits and creative possibilities. It is these, along with the technical and psychoacoustic underpinnings, that I will expand upon in upcoming blog posts.
If there are any aspects of spatial audio that you’d like to have explained then leave a comment below.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.